
Problem Definition
Many second-generation immigrants experience challenges when communicating with their grandparents and relatives as they often do not fluently speak a common language. For example, a grandson who speaks limited Chinese and grandparents who do not speak English may only be able to talk about simple topics, such as greetings or daily routines, and rarely engage in meaningful conversations.
My Idea
This project began from my experience as a second-generation immigrant and the challenges I faced when talking with my grandparents. I found it difficult to translate my thoughts to Chinese, and couldn’t understand many of the things that they were saying.
My idea is to use AI to create an app that can translate my speech in real-time, while mimicking my voice. Given the time constraints, the final product will likely be software running on a laptop rather than on a phone. The prototype will need to recognize speech input, translate between English and Chinese, and deliver output as quickly as possible while using personalized voices for each speaker.
Target Users
This project is designed to facilitate intergenerational communication. It can be useful for immigrant families. More broadly, it can be used among friends and any close relationships with language barriers to strengthen their bonds to bring them closer.
Existing Solutions
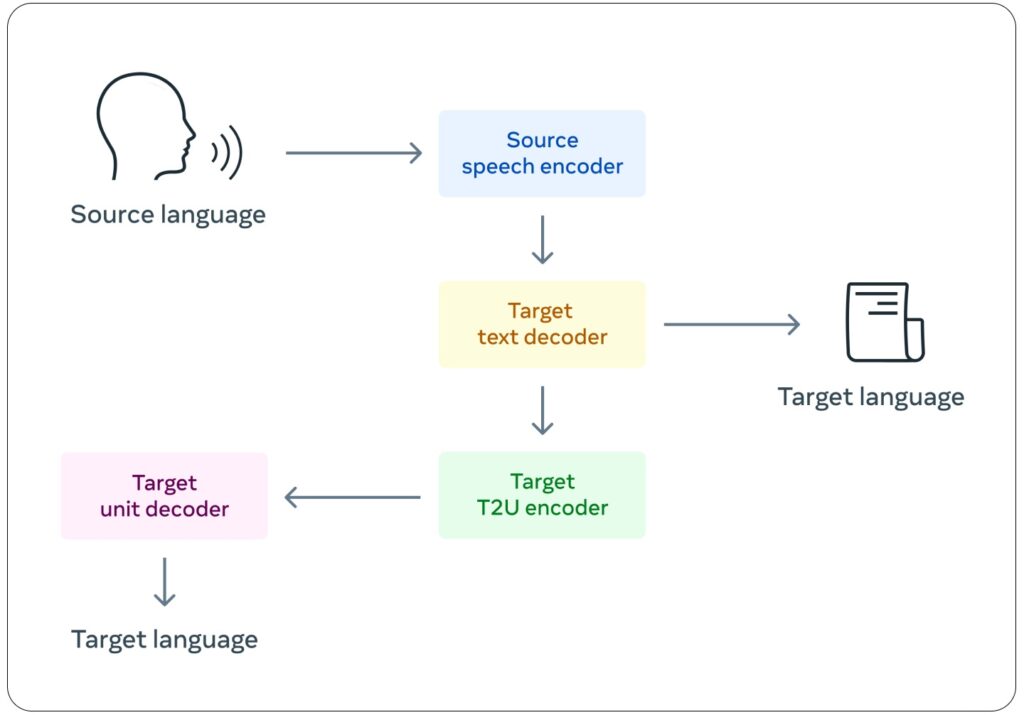
There have been many available products with some form of speech translation, such as smartphone apps, earbuds, and portable devices. These products are broadly used for travelling, multilingual conferences, customer service, and education. They are developed to support general situations. Most of these current products use a 3-model pipeline* and are designed for broader public use. So they have common limitations in generating personalized human voice and real-time translation. More specifically:
- Cascading delays prevent real-time translation as each model adds a delay.
- Errors will propagate across models. If one of the models has an error, that error will pass and grow through the layers.
- It is hard to preserve the emotions and expressions across the conversion from audio to text and back to audio, especially across different languages.
3-Model Pipeline:
- ASR – Automatic Speech Recognition to transcribe speech to text
- Open AI’s Whisper
- Meta’s Wave2Vec2
- Qwen3 ASR
- LLM – Large Language Model to translate text
- Google Neural Machine Translation
- Meta’s M2M-100 and No Language Left Behind (NLLB)
- TTS – Text-to-speech to speak the translation.
- Microsoft’s Azure Neural TTS
- Meta’s SeamlessExpressive
- Qwen3 TTS
There are newer models that are end-to-end speech translation models. Rather than having 3 separate models, these models directly translate from audio input to audio output without any middle steps or models. This will improve the time delay of the translation, but the main downsides are its massive size and the large amount of data required to train or fine-tune it.
My Solution
My solution is meant to add onto and improve the existing 3 model pipeline. Luckily, there are many open-source and free models online for Automatic Speech Recognition (ASR), translation, and text-to-speech (TTS). I will start-off with pretrained models, then I can fine-tune them and adjust the pipeline as necessary to achieve the following goals:
- Be able to respond in parallel with input speech. For example, if I were to talk for 10 seconds, rather than waiting for me to finish talking, it would immediately begin to process my speech, and start outputting translated speech while I am still talking.
- Have a personalized TTS model that can mimic the speech of the person who is actually speaking, even across languages, so it feels more personalized and like two people in an actual conversation.
Task Schedule
Stage 1: Create and test a simple pre-trained 3-model pipeline. (Deadline: February 26th, 2026)
- Setup in Google Colab
- Use pre-trained Hugging Face models
- Test the 3 models together in the pipeline
- ASR model
- LLM Translation model
- TTS model
Stage 2: Collect Data (Deadline: March 7th, 2026)
- Speech data with transcription
- Record in English and Chinese
- Fed into both ASR and TTS models for fine-tuning
- Language translation data
- Optional as the pre-trained model may already be good enough
- Focus on more day-to-day and colloquial language.
Stage 3: Fine-tune model and adjust pipeline (Deadline: April 13th, 2026)
- Fine-tune the small details of the 3 models
- Add improvement features
- Parallel translation
- Personalized voice
Stage 4: Finish first demo (Deadline: April 17th, 2026)
- Testable demo for testers (approximately 6 to 8 people)
- Use fine-tuned and adjusted models.
- Implement easy-to-use speech input
- Implement output speech from speaker
- Design user-friendly UI and UX
- Design a google form for testing feedback.
Stage 5: Test Demo (Deadline: April 23th, 2026)
- Share demo with testers
- Receive feedback for the demo
Stage 6: Post-test optimization (Deadline: April 30th, 2026)
- Apply feedback from first demo
AI Transparency Statement
AI was not used.
Leave a Reply to mcrompton Cancel reply